OKEx领先的数字资产交易平台
OKEx是全球著名的数字资产交易平台之一,支持币币交易、合约交易、ETT组合交易、OTC交易等各种交易服务。OKEx是全球领先的比特币交易平台,使用银行级别的SSL加密和冷存储等技术,为用户提供安全稳定的比特币、莱特币、以太坊、BCH、量子链、Ripple、NEO、EOS、HSR等数字资产交易服务。安全性极高,且不用翻墙。
OKEx是全球著名的数字资产交易平台之一,支持币币交易、合约交易、ETT组合交易、OTC交易等各种交易服务。OKEx是全球领先的比特币交易平台,使用银行级别的SSL加密和冷存储等技术,为用户提供安全稳定的比特币、莱特币、以太坊、BCH、量子链、Ripple、NEO、EOS、HSR等数字资产交易服务。安全性极高,且不用翻墙。

OKEx客户端支持ios、andriod等系统
OKEx国内可以访问.各种浏览器适用.
目前有OKEx钱包、OKEx资讯等周边软件

OKEx网交易平台是一群数字资产爱好者创建而成的一个专注区块链资产的交易平台。 OKExapp为用户提供更加安全、便捷的区块链资产兑换服务,聚合全球优质区块链资产, OKEx网交易所致力于打造世界级的区块链资产交易平台。
立即注册OKEx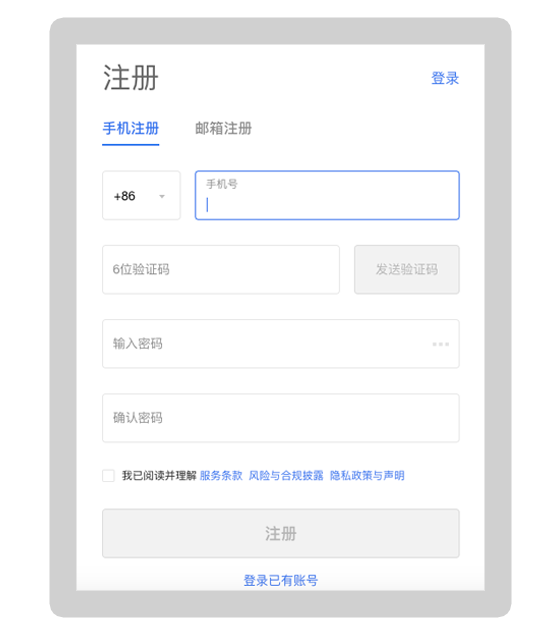
通过使用发现以网页版注册最快捷便利。登录OKEx.com点击立即注册即可。整个流程非常简单。后续如果需要更高的安全操作可以通过手机验证等方式提高账户的安全性。


现在OKEx网法币交易越来越便捷。无论是通过网页版还是手机版门槛已经比之前低了很多。 更推荐网页版多一些。流程和信息更清楚,如果您熟悉手机操作也很简单,选择OKEx网“法币交易”即可。
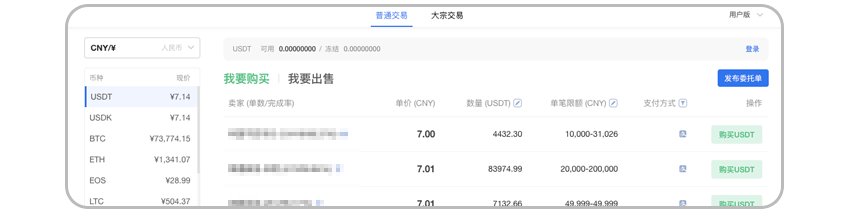
OKExapp 苹果手机客户端下载.
OKExapp 安卓手机客户端下载.
本站将OKEx注册使用最常见的问题进行了解析。您应该对OKEx网有了更多的了解。
通过本站让您使用过程更会顺畅。尤其是客户端下载的地方建议点开网址详细查看。
如果觉得本站对您有帮助,或是有朋友想了解,请将本站转发给他。也是对我们最大的鼓励!
- 点击下面图标即可转发 -